
Twitter Sentiment Analysis – Python
Introduction
In this blog we will see that what sentiment analysis is and why we do it. Then we will perform sentiment analysis on twitter data. In the last step we will make a model to predict if a tweet is either positive, negative or neutral.
What is sentiment analysis?
Sentiment Analysis is the process of ‘computationally’ determining whether a piece of writing is positive, negative or neutral. It’s also known as opinion mining, deriving the opinion or attitude of a speaker.
Why sentiment analysis?
- Business: In marketing field companies use it to develop their strategies, to understand customers’ feelings towards products or brand, how people respond to their campaigns or product launches and why consumers don’t buy some
- Politics: In political field, it is used to keep track of political view, to detect consistency and inconsistency between statements and actions at the government level. It can be used to predict election results as well!
- Public Actions: Sentiment analysis also is used to monitor and analyze social phenomena, for the spotting of potentially dangerous situations and determining the general mood of the blogosphere.
Data set selection
As we are talking about twitter sentiment analysis so the data that I have used is twitter data of a certain user.
This is the preview of the data set
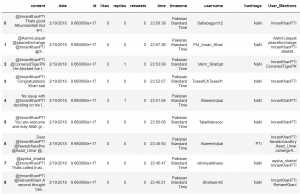
Data Preprocessing/refinement
This was a bit tricky part, but it was interesting to do. I had to clean the data and get only the content from the tweet. I removed the hashtags, user names, user mentions and other web links. I did this so that later when I will apply sentiment analysis it will perform smoothly.
Sentiment Analysis - a brief summary
To get the scores of the sentiment analysis, I have used NLTK sentiment vader library.
What is sentiment vader?
VADER belongs to a type of sentiment analysis that is based on lexicons of sentiment-related words. In this approach, each of the words in the lexicon is rated as to whether it is positive or negative, and in many cases, how positive or negative. Below you can see an excerpt from VADER’s lexicon, where more positive words have higher positive ratings and more negative words have lower negative ratings.
For me sentiment vader is the best analyzer for social media. This is because it can handle emoticons, punctuation marks and acronyms. It is also context based.
Now coming back to our data set. When we apply the sentiment vader on a sentence then in return we get four values, positive, negative, neutral and compound, where compound value is the over all score of the sentence.
Here is the code that shows the computation of the sentiment vader.
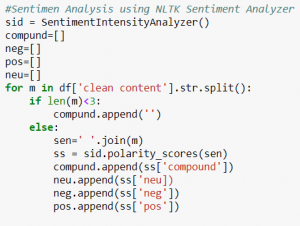
If you analyze one sentence then you’ll see something like this.

After getting all the scores from the tweets this is what the data set looked like.
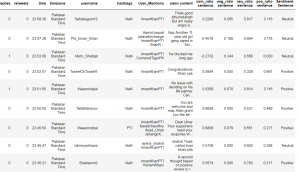
The above data frame columns “com_ratio sentence”, “neg_ratio sentence”, “neu_ratio sentence” and “pos_ratio sentence” are the scores that are generated after applying sentiment analysis. We will need these scores when we will build our model to predict that whether the tweet is positive, negative or neutral.
Developing model for prediction
Our data is now ready as it has now all the values that are required to put in the model.
The model that I have chosen is Naive Bayes Model. It is a good model for classification. The total number of tweets that I had were 4500 and I manually classified 1500 tweets so that it can be trained for the model. Out of the 1500 tweets the classifier splitted the data into 1200 and 300, train and test data respectively. Although the results were not quiet satisfying on the test data as it was not telling us about all categories, but I still went with it because in the tweets there were many tweets which were not in english, they were in roman urdu.
Following is the snapshot of the code,
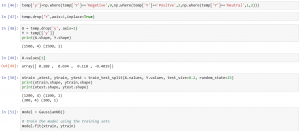
Conclusion
The results of the model were not very accurate but they were satisfactory. The main reason for this is the presence of roman urdu sentences. I previously did not built any model and just based on the sentiment values I categorized them. This in result produced very poor outcome. When I applied the model on it then it some what made the outcome more sensible and accurate. That’s all folks, I hope this blog will benifit you. To learn more about sentiments you can visit here.